
The race to build the smartest artificial intelligence is tighter than ever.
Using data from TrackingAI, this ranking—originally featured as part of Visual Capitalist’s AI Week (sponsored by Terzo)—benchmarks the world’s leading AI systems on the Mensa Norway IQ test as of April 2026.
The results reveal exactly who is leading the pack today, and just how little separates the top contenders at the frontier of AI development.
A Tie at the Top: The 2026 Leaderboard
This ranking provides a snapshot of how well today’s top AI models perform on abstract, visual pattern-recognition tasks. As the table below shows, a difference of just a few points can completely shift the rankings.
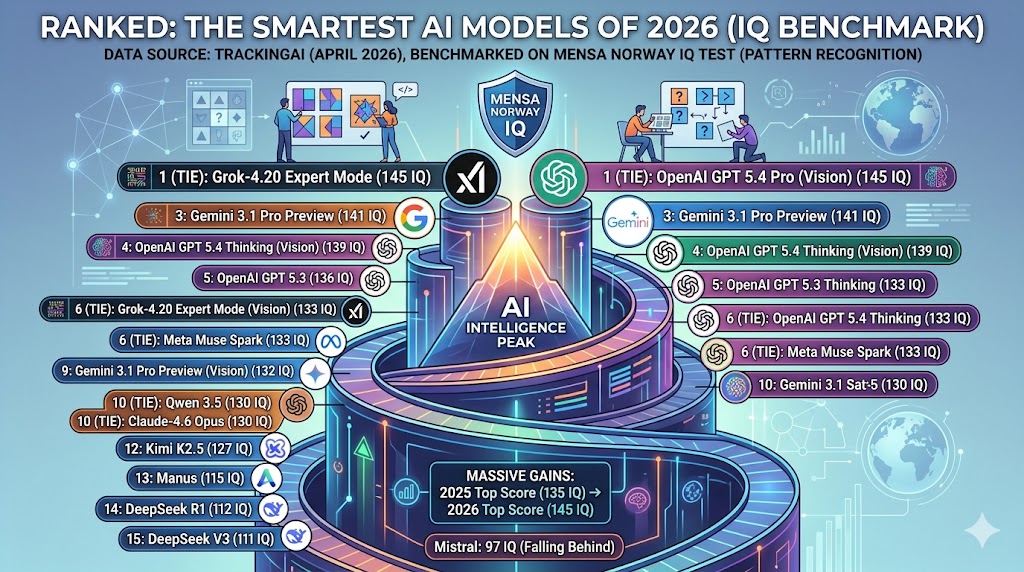
| Rank | AI Model | Mensa Norway IQ Score (April 2026) |
| 1 (Tie) | Grok-4.20 Expert Mode | 145 |
| 1 (Tie) | OpenAI GPT 5.4 Pro (Vision) | 145 |
| 3 | Gemini 3.1 Pro Preview | 141 |
| 4 | OpenAI GPT 5.4 Thinking (Vision) | 139 |
| 5 | OpenAI GPT 5.3 | 136 |
| 6 (Tie) | Grok-4.20 Expert Mode (Vision) | 133 |
| 6 (Tie) | OpenAI GPT 5.4 Thinking | 133 |
| 6 (Tie) | Meta Muse Spark | 133 |
| 9 | Gemini 3.1 Pro Preview (Vision) | 132 |
| 10 (Tie) | Qwen 3.5 | 130 |
| 10 (Tie) | Claude-4.6 Opus | 130 |
| 12 | Kimi K2.5 | 127 |
| 13 | Manus | 115 |
| 14 | DeepSeek R1 | 112 |
| 15 | DeepSeek V3 | 111 |
Key Takeaways
- The Top is Crowded: The biggest takeaway is how compressed the top of the leaderboard has become. Grok-4.20 Expert Mode and OpenAI GPT 5.4 Pro (Vision) are perfectly tied for first place, with Gemini 3.1 Pro Preview trailing closely behind.
- Massive Year-Over-Year Gains: The speed of improvement is staggering. In 2025, the top score on this exact benchmark was 135. Just one year later, the ceiling has been pushed up to 145.
- Falling Behind: Not all developers are keeping pace. Among major AI companies, Mistral’s top model currently ranks the lowest in this dataset with a score of 97—putting it well below the leading group.
How the Test Works (And Why It Matters)
The Methodology TrackingAI uses the public Mensa Norway test, which consists of 35 visual-pattern puzzles. To test non-vision models, the visual questions are translated into text descriptions. Vision models, on the other hand, are fed the original images directly. (Note: If a model refuses to answer a question, it is prompted up to 10 times, and the most recent answer is recorded).
The Caveats While TrackingAI’s leaderboard is a fantastic, familiar way to track reasoning performance over time, it is not a definitive measure of “general intelligence.”
- Because the test is highly visual, scores can fluctuate depending on exactly how the questions are presented to the AI.
- An IQ-style benchmark only captures one specific slice of cognitive capability. It does not measure other crucial real-world skills, such as coding proficiency, factual reliability, professional domain expertise, or the ability to accurately use digital tools.